AI economics break when usage scales.
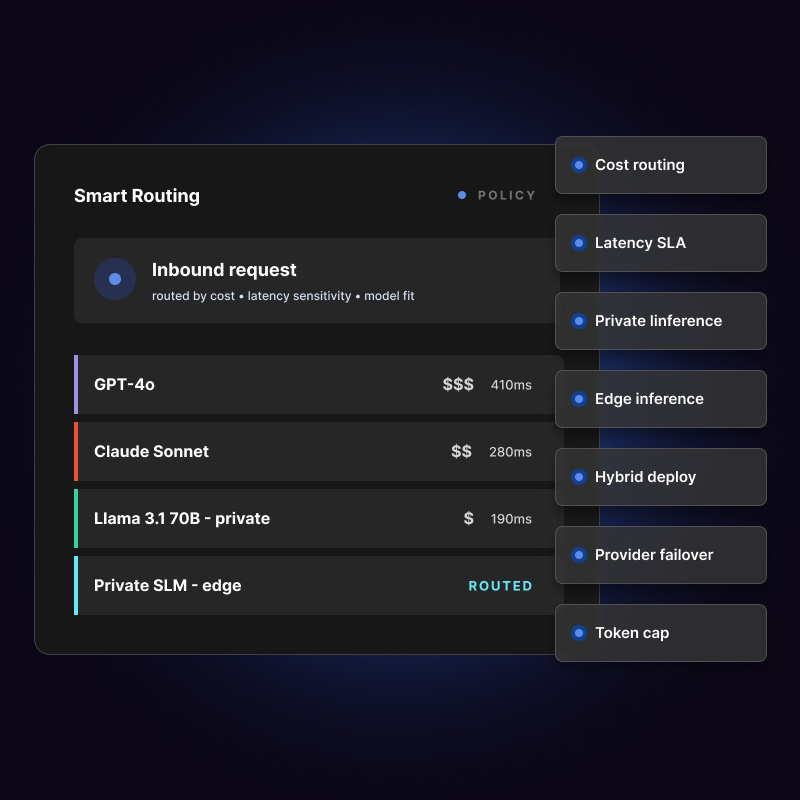
Enterprise AI pilots often look affordable until adoption grows across teams, agents, documents, and workflows. Runtime strategy becomes a board-level cost and performance question.
Iterate combines Generate, Lifeboat, and AgentWatch to improve AI execution economics across private, public, edge, and hybrid environments.
Optimize AI runtimes, routing, cost, latency, resilience, and deployment across public, private, edge, on-prem, and hybrid environments.
Combine Iterate products into a governance architecture that gives teams AI access while preserving visibility, control, and accountability.
Enterprise AI governance should reduce risk without forcing teams back into experimentation silos.