
Reduce inference spending by 75% to 95% with more efficient model execution.
Deliver 2 to 3 times faster inference for more responsive AI applications.
Cut energy use and cooling needs by running AI workloads more efficiently.
Improve performance across Intel, AMD, NVIDIA, and Qualcomm hardware.
Optimizes memory, batching, and parallelization to deliver real-time performance while cutting compute and energy usage by up to 95 percent.
Works across cloud, on-prem, containers, air-gapped sites, and edge devices so your AI can operate in any environment you choose.
Boosts performance on Intel, AMD, Qualcomm, and NVIDIA hardware, including constrained edge accelerators.
Runs fully inside your walls with no cloud dependency, no external traffic, and no data exposure.
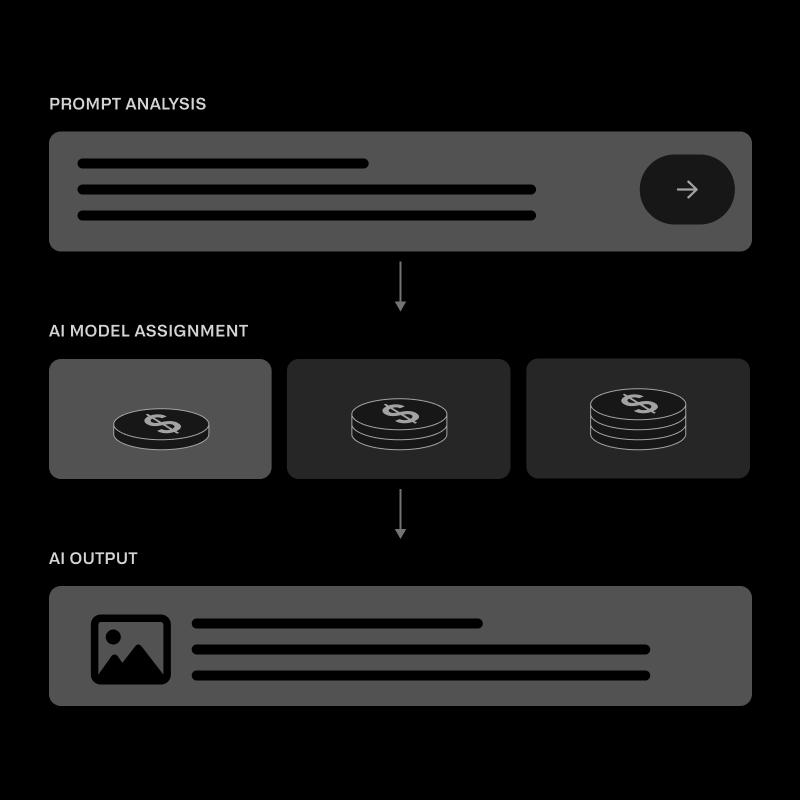
AI agents multiply the number of inference calls by 10–100×. Without Runtime, costs skyrocket.
With Runtime:
This is why leading enterprises use Runtime as their agent infrastructure layer.

12x Cheaper & 6x Faster than Cloud Inference
A global retail deployment saw dramatic improvements using their existing servers with no new GPUs.
Runtime adapts to every environment including enterprise stacks, hyperscale data centers, OEM hardware, and offline edge deployments, so you can run AI anywhere.
Interplay Runtime turns every piece of hardware into an AI-optimized machine.
All with a lightweight, invisible software layer.


Talk to our team to see how Runtime can reduce your costs and supercharge your AI performance.