
All build AI capacity, but without orchestration they compete on price, not performance.
NVIDIA gained an edge with NIM. Intel, AMD, and Qualcomm need equivalent orchestration and runtime intelligence.
Rebuild the same plumbing—tokenization, inference, orchestration—again and again.
Integrate across any hardware (Intel, AMD, Qualcomm, NVIDIA)
Deploy In any environment (cloud, edge, or air-gapped)
Built-in runtime for 75–95% cost and speed efficiency
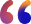
Together, they form the world’s first end-to-end orchestration and runtime environment for private AI at scale.
Visual interface where developers create complete AI systems in days instead of months.

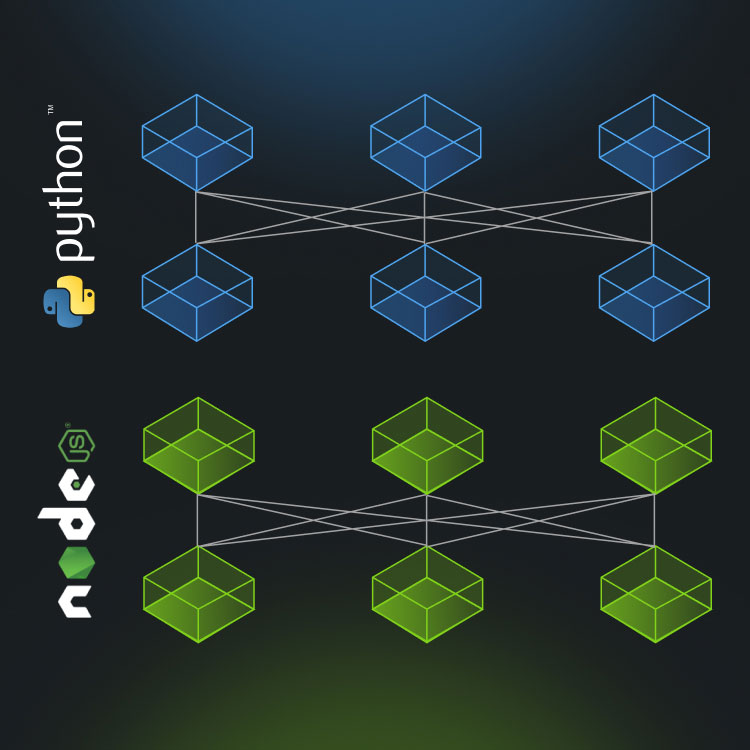
An autonomous enterprise coding agent that generates and hardens code with 17 security scans, OWASP rules, and automated documentation. Integrates directly into Studio, or runs standalone, executing inside Interplay’s secure runtime.


Interplay’s modular architecture is protected by multiple U.S. patents covering:
Together, they form a three-layer moat around modular, composable AI.

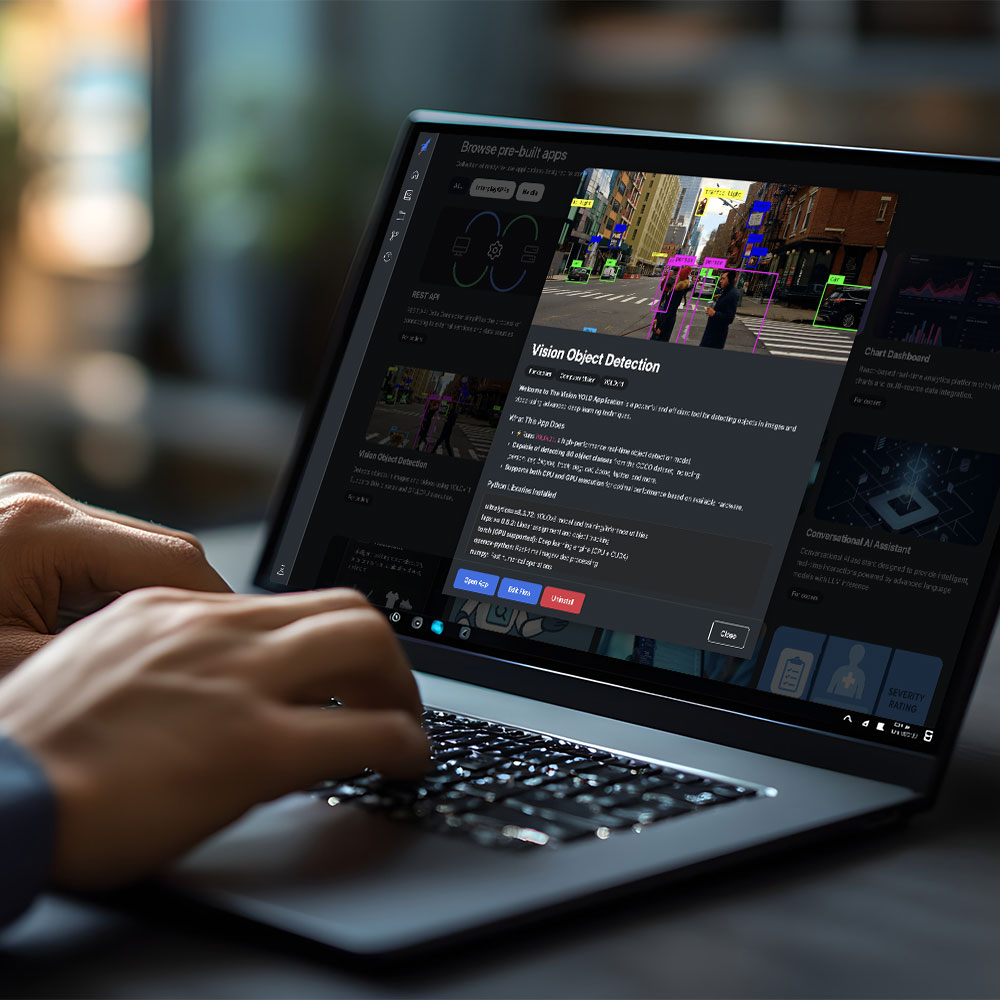
Discover how Interplay Microservices transforms data centers, chips, and enterprises into AI-ready environments, without the cloud.